![[Tensorflow / Deep learning] 보스턴 집값 예측](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FoskyH%2FbtrSnV0pVj5%2F2phfZfY6hUZUwiUGRcM8lK%2Fimg.png)
전 포스팅은 간단한 하나의 독립변수로 모델을 만드는 예제를 해보았다.
이번엔 독립변수가 여러개일 경우 모델을 만들어 예측을 하는 방법을 알아보겠다.
아래 이미지는 1978년도 보스턴주의 506개 동네의 집값을 보여주는 표이다.
해당 표에서의 첫번째 행에서 1 ~ 13번 열 까지는 도시를 나타내는 독립변수이다.
마지막 14번째 열은 집값을 해당 도시의 집값의 중앙값을 보여준다.
그럼 왼쪽의 공식은? 이 독립변수들이 어떻게 종속변수에 영향을 미치는지를 보여준다.

위의 공식을 적용하여 여러 행들 중, 하나를 선택하여 적용해보자.
그 예시가 아래 이미지와 같다.

이와 같이 각각의 독립변수들은 모두 종속변수에 영향을 준다.
그렇다면 딥러닝의 조건 4가지를 위의 데이터를 대입하여 정리해보자.

독립변수는 1 ~ 13열 까지이고, 마지막 14열이 종속변수이다.
그렇기에 X layers의 shape 수가 13이고, 종속변수가 medv 하나이기에 Dense의 값은 1이된다.
그럼 하나의 독립변수 여러개가 어떠한 값에 의해 종속변수의 값으로 반환되는 것을 이미지로 표현한게 아래 이미지이다.

위의 이미지를 자세하게 살펴보자.
전 포스팅에서 말했듯, 독립변수와 종속변수 하나를 사용할 경우 하나의 뉴런을 사용한다고 빗대어 표현하였다.
뉴런은 실제로 존재하는 말이기에, 이와같은 인공신경망에서는 퍼셉트론이라고 한다.

위의 이미지는 1 ~ 13열 까지의 총 13개의 독립변수와 하나의 종속변수를 사용하였을 경우의 공식이다.
y = w1x1 + w2x2 + ........ + w13x13 + b
여기서 w는 가중치를 말하고, 위에서의 b는 편향을 말한다.
만약 종속변수가 두개일경우는 어떨까? 아래이미지에서 확인해보자.
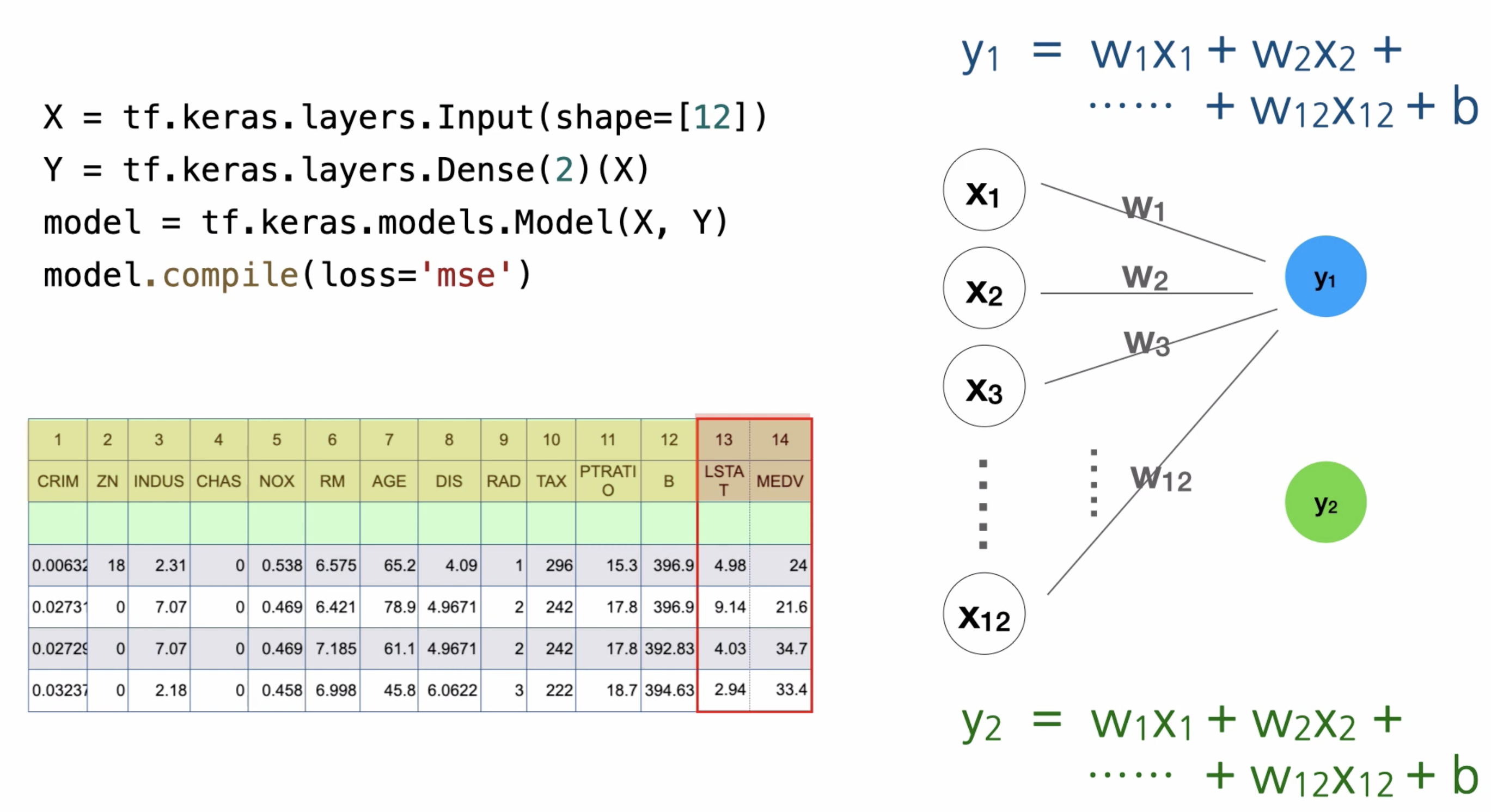
만약 독립변수가 12개, 종속변수가 2개일 경우 총 계산해야되는 수는
y1의 독립변수 12번, 그리고 y1 편향 1번, 총 13번
y2의 독립변수 12번, 그리고 y2 편향 1번, 총 13번
즉 26번의 연산을 거치게 된다.
그럼 이제 본격적으로 코드를 보자.
실제로 퍼셉트론이 1개일때와 12개일때와 코드의 큰 차이는 없다.
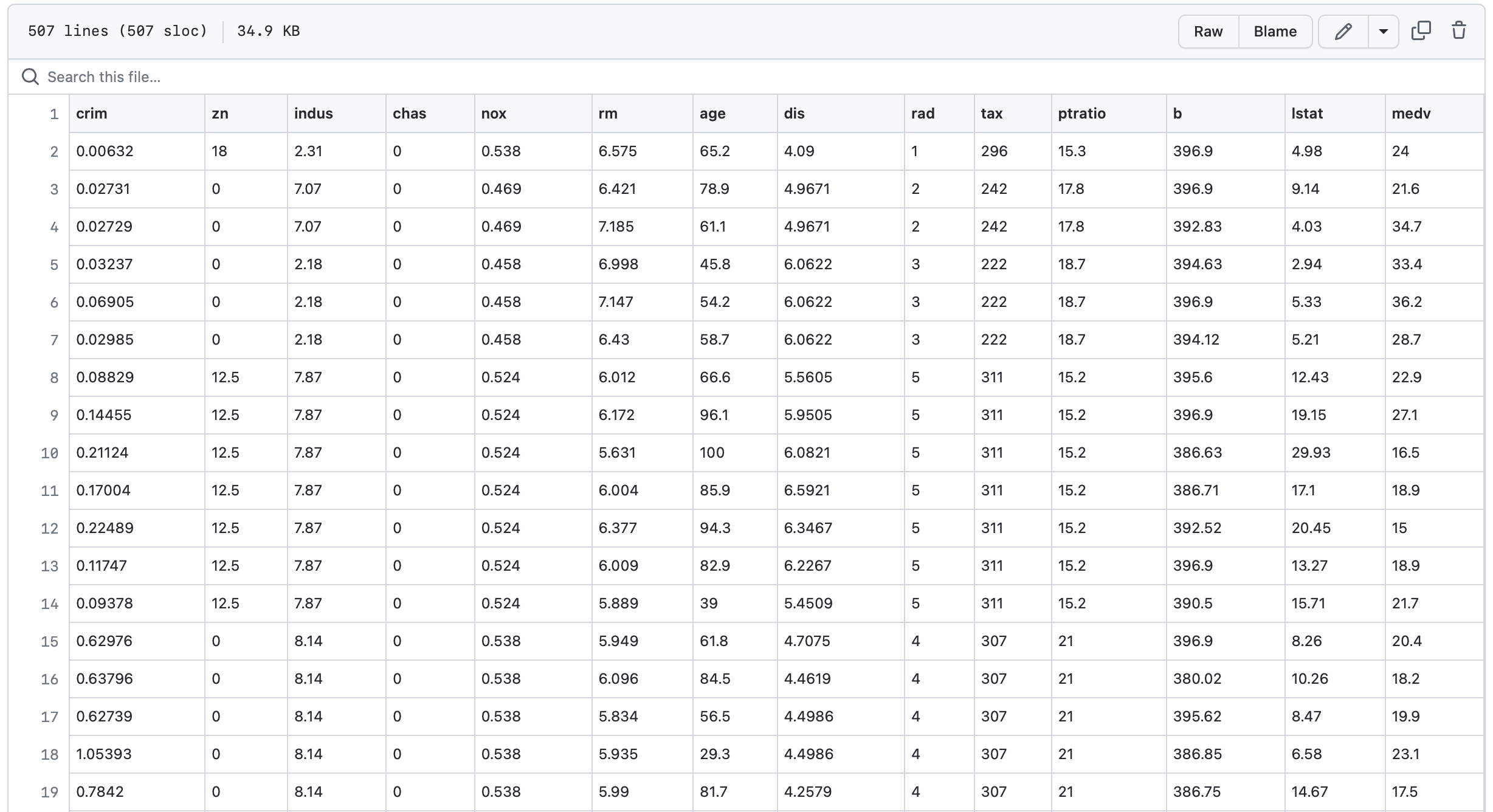
과거 참조할 데이터이다. 너무 많아서 일부만 잘랐다.
그럼 실제로 해당 데이터들을 학습 시킨 후, 제공되는 과거 데이터와의 차이를 확인해보자.
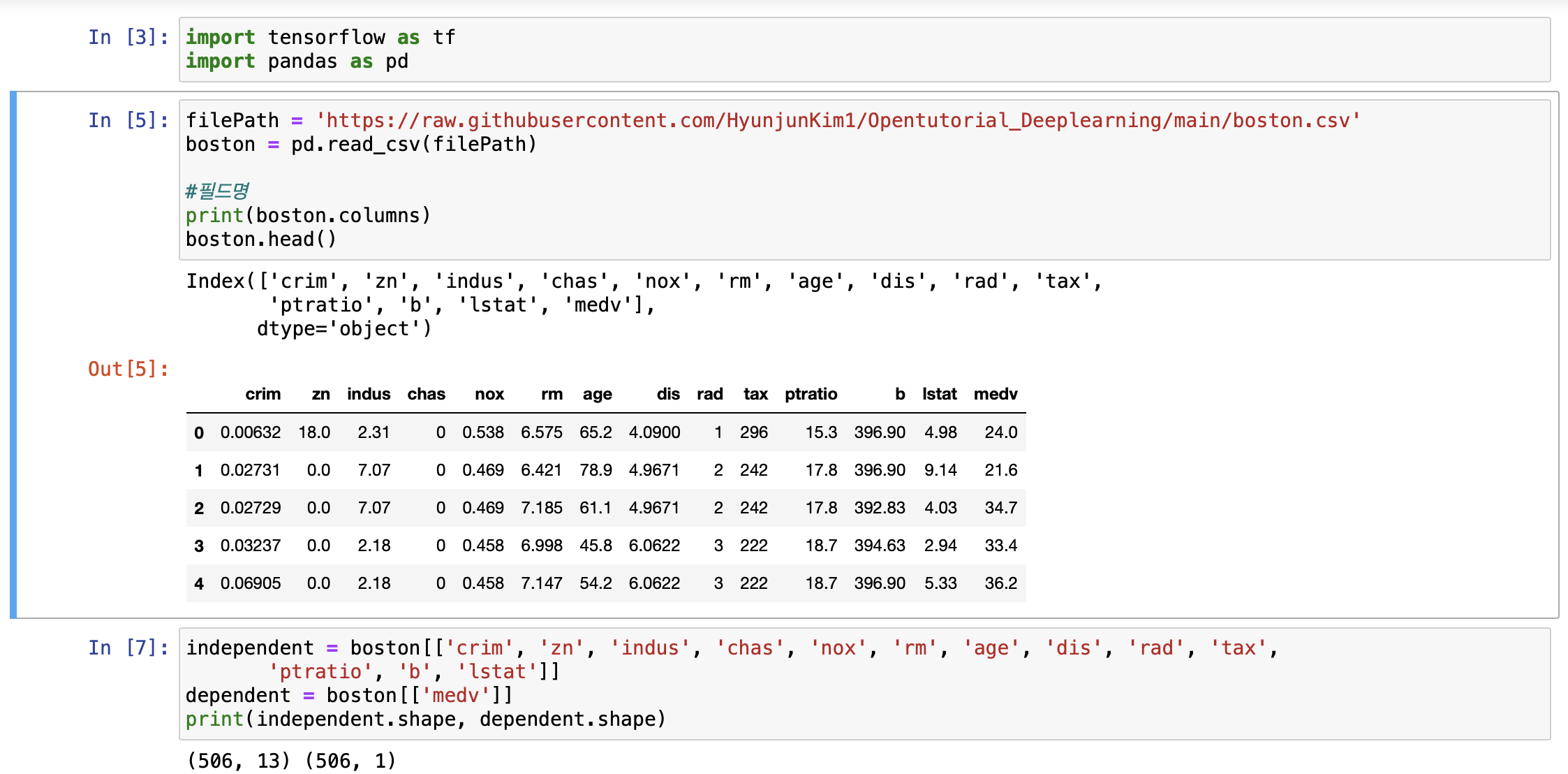
우선 filePath의 경로는 아래를 참조하자.
https://raw.githubusercontent.com/HyunjunKim1/Opentutorial_Deeplearning/main/boston.csv
boston에 저장되어있던 csv 파일의 값들을 입력하도록 하고 제대로 입력되었는지 확인해준다.
이후 제대로 입력되었는지 확인을 위해 독립변수와 종속변수를 shape로 출력해보자.
(506, 13) (506, 1) 각각 독립변수 13개, 종속변수 1개 올바르게 출력된 것을 확인할 수 있다.
이후 모델을 만들어서 학습 시켜준다.
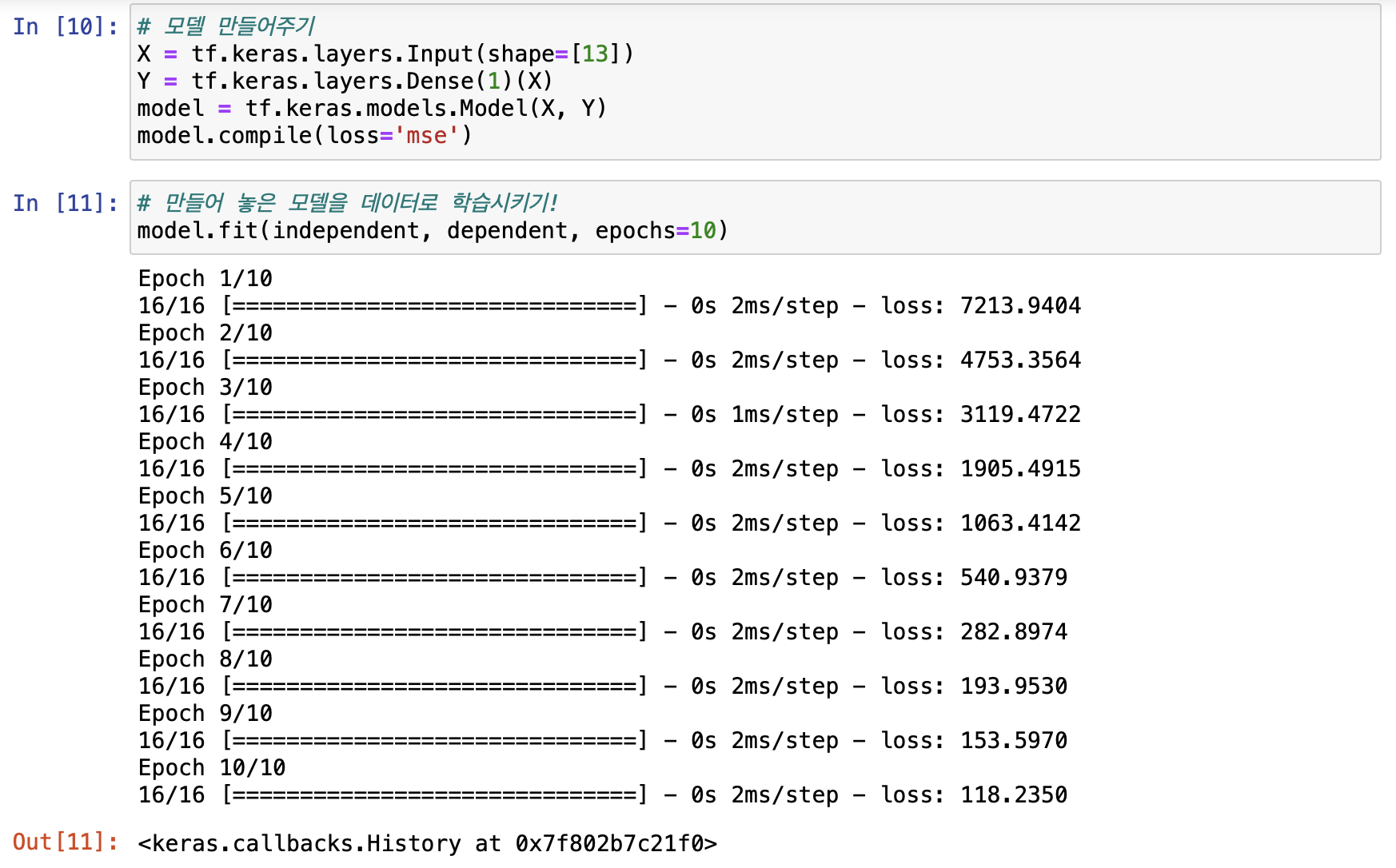
학습 시켜주고나니 ... loss율이 너무 크다. 0에 가까울수록 학습이 잘된거라고 하였으나 0과는 거리가 멀다.
이렇게 loss가 일정하게 줄어들고 있을 경우 학습을 더 시켜도 더 줄어들 확률이 높다는 뜻이기에
다시한번 10000번 정도 표기안되게 학습 시키고, 10번을 더 학습시켜 출력해보자.
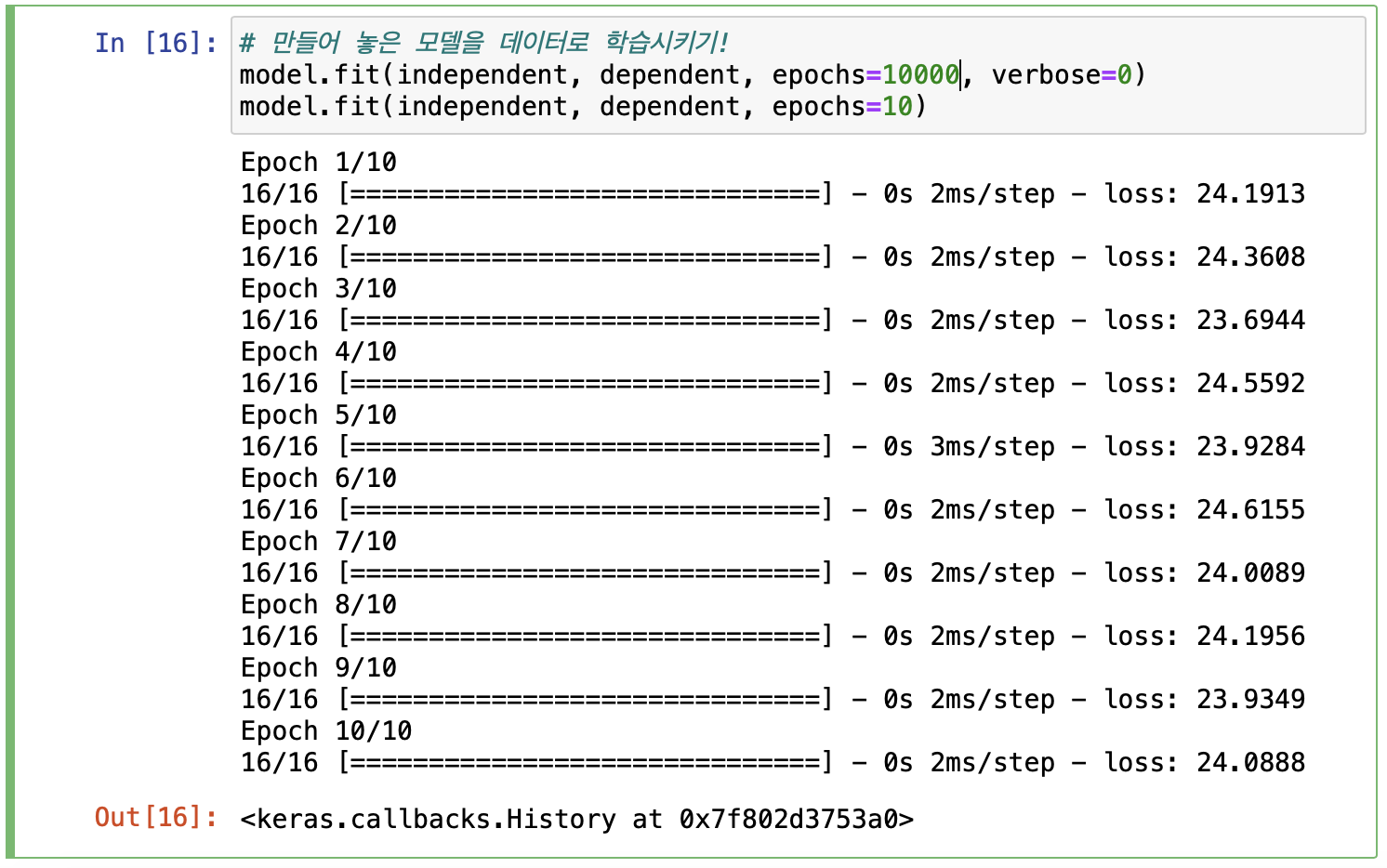
그렇게 해보니, 23 ~ 24를 반복하는게 보이니 더이상 학습을 시켜도 의미가 없어보인다.
그럼 학습시킨 모델을 출력하여 실제 종속변수와 값을 비교해보자.
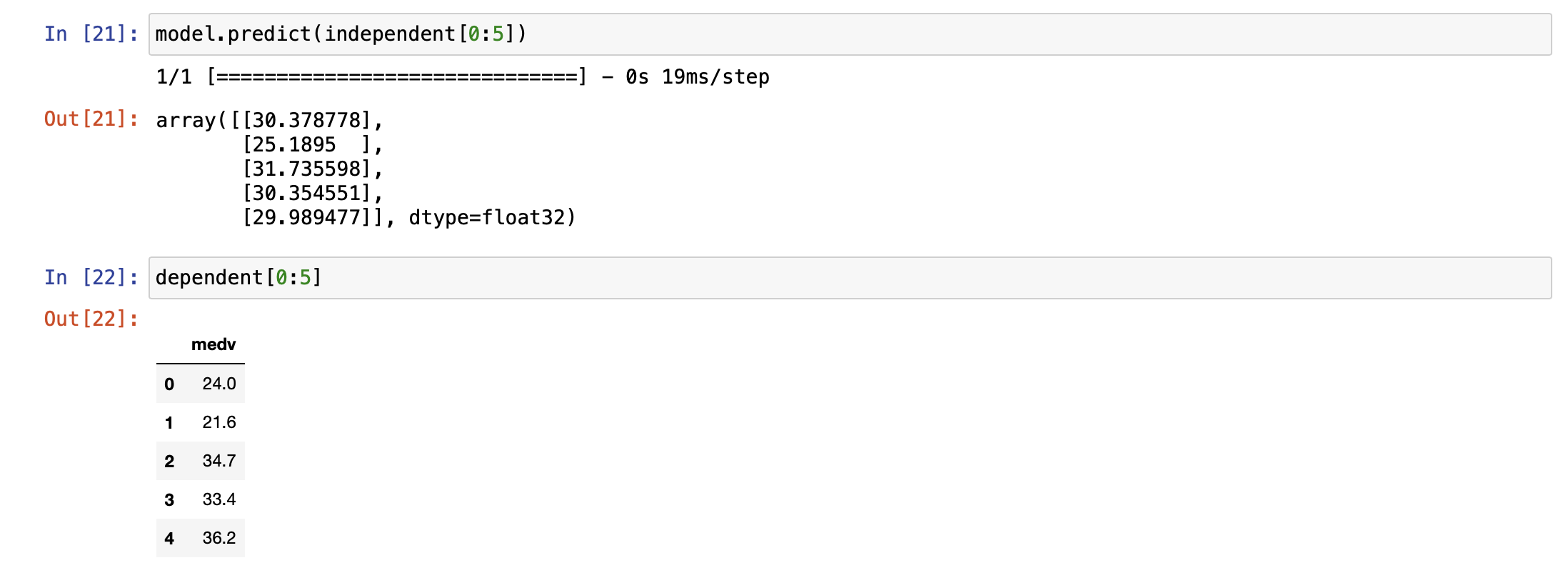
학습된 모델에 독립변수의 0번째부터 5개의 인덱스 까지 입력하여 출력해보자.
실제로 종속변수의 값과 조금의 차이는 있으나, loss를 생각하면 올바르게 잘 학습 된것으로 보인다.
30.378778 <--> 24.0
25.1895 <--> 21.6
31.735598 <--> 34.7
30.354551 <--> 33.4
29.989477 <--> 36.2
이후 처음 이미지의 왼쪽 공식과 비교를 해보자.
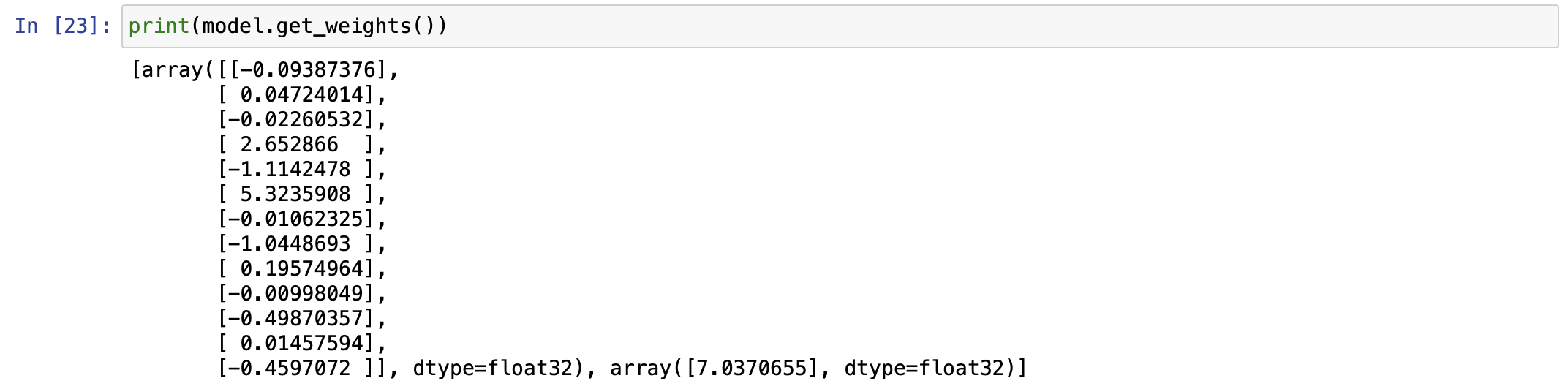
딥러닝을 이용하면 단 몇분만에 위와 같은 공식을 만들어버린다.
사람이 일일히 계산하려면 오래걸리는걸 보다 쉽게 할 수 있게 된다.
아래는 전체 코드이다.
Code ( Python )
import tensorflow as tf
import pandas as pd
filePath = 'https://raw.githubusercontent.com/HyunjunKim1/Opentutorial_Deeplearning/main/boston.csv'
boston = pd.read_csv(filePath)
#필드명
print(boston.columns)
boston.head()
independent = boston[['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax',
'ptratio', 'b', 'lstat']]
dependent = boston[['medv']]
print(independent.shape, dependent.shape)
# 모델 만들어주기
X = tf.keras.layers.Input(shape=[13])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 만들어 놓은 모델을 데이터로 학습시키기!
model.fit(independent, dependent, epochs=10000, verbose=0)
model.fit(independent, dependent, epochs=10)
model.predict(independent[0:5])
dependent[0:5]
print(model.get_weights())참조
https://www.youtube.com/channel/UCOAyyrvi7tnCAz7RhH98QCQ
봉수골 개발자 이선비
봉수골에서 개발과 강의하는 걸 좋아하여 개발과 강의를 하며 살아가는 이선비입니다.
www.youtube.com
'🔥 Programming > ML & DL' 카테고리의 다른 글
| [Tensorflow / Deep learning] 은닉층 (Hidden Layers) (0) | 2022.12.03 |
|---|---|
| [Machine learning] One-hot encoding와 Softmax Regression, Cross-entropy란? (0) | 2022.11.30 |
| [Tensorflow / Deep learning] 아이리스 품종 분류 (0) | 2022.11.30 |
| [Tensorflow / Deep learning] 레모네이드 판매 예측 (0) | 2022.11.28 |