![[Tensorflow / Deep learning] 아이리스 품종 분류](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FsATR1%2FbtrSvAI2sHf%2FWef2nHx86cnHWZnvxZDXX1%2Fimg.png)
아이리스 품종 분류 예제를 풀어보기 전 머신러닝에 대해 간단하게 알아보자.
머신러닝은 크게 3가지로 분류가 된다.
- 강화학습
- 지도학습
- 비지도학습
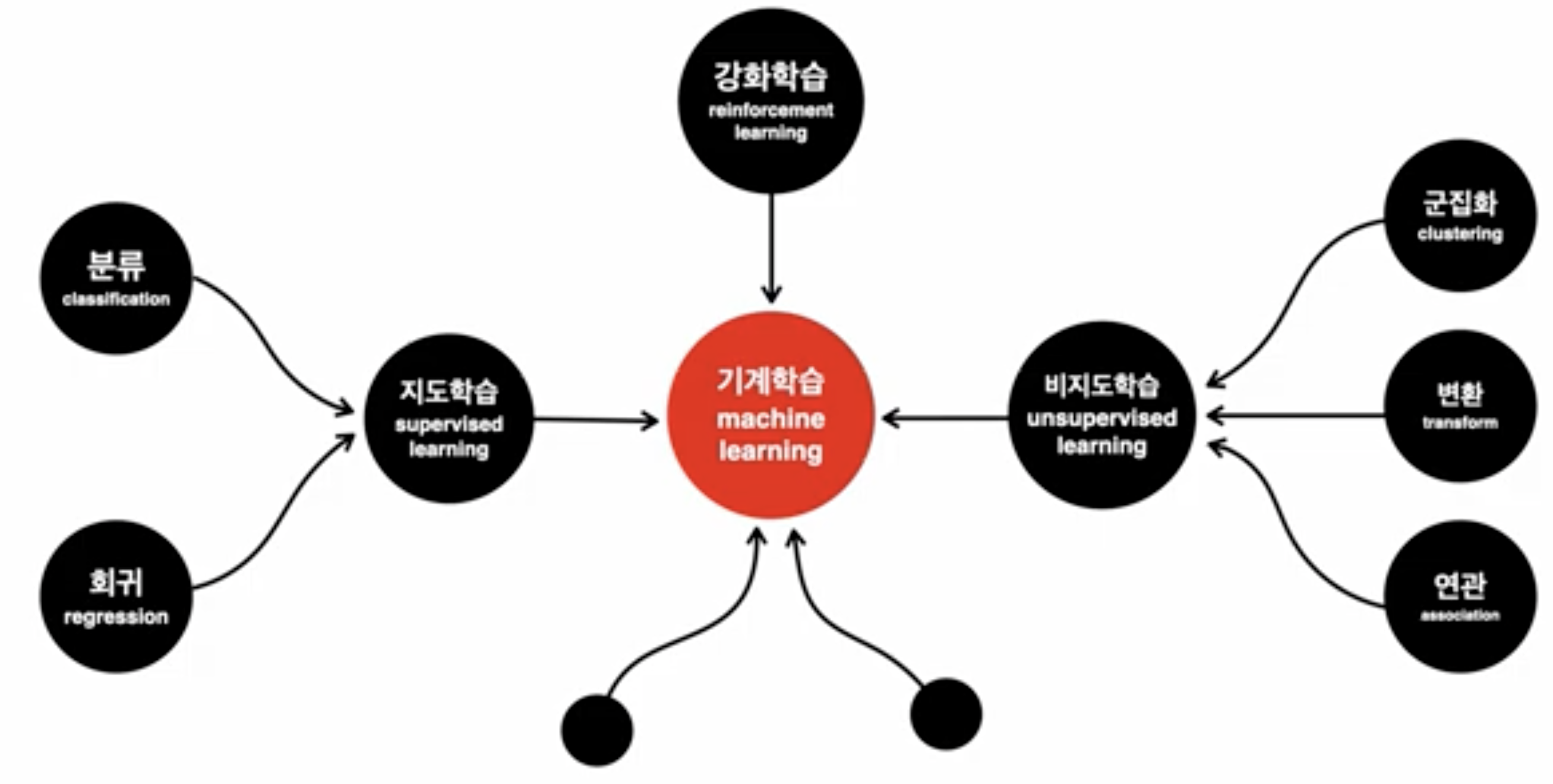
우선 우리가 예제를 풀었던 보스턴 집값 예측이나, 레모네이드 값 예측과 같이
딥러닝 및 AI라고 불리는 것들은 전부 지도학습에 속한다.
여기서 지도학습의 분류와 회귀의 개념에 대해 정말 간단하게 알아보자.
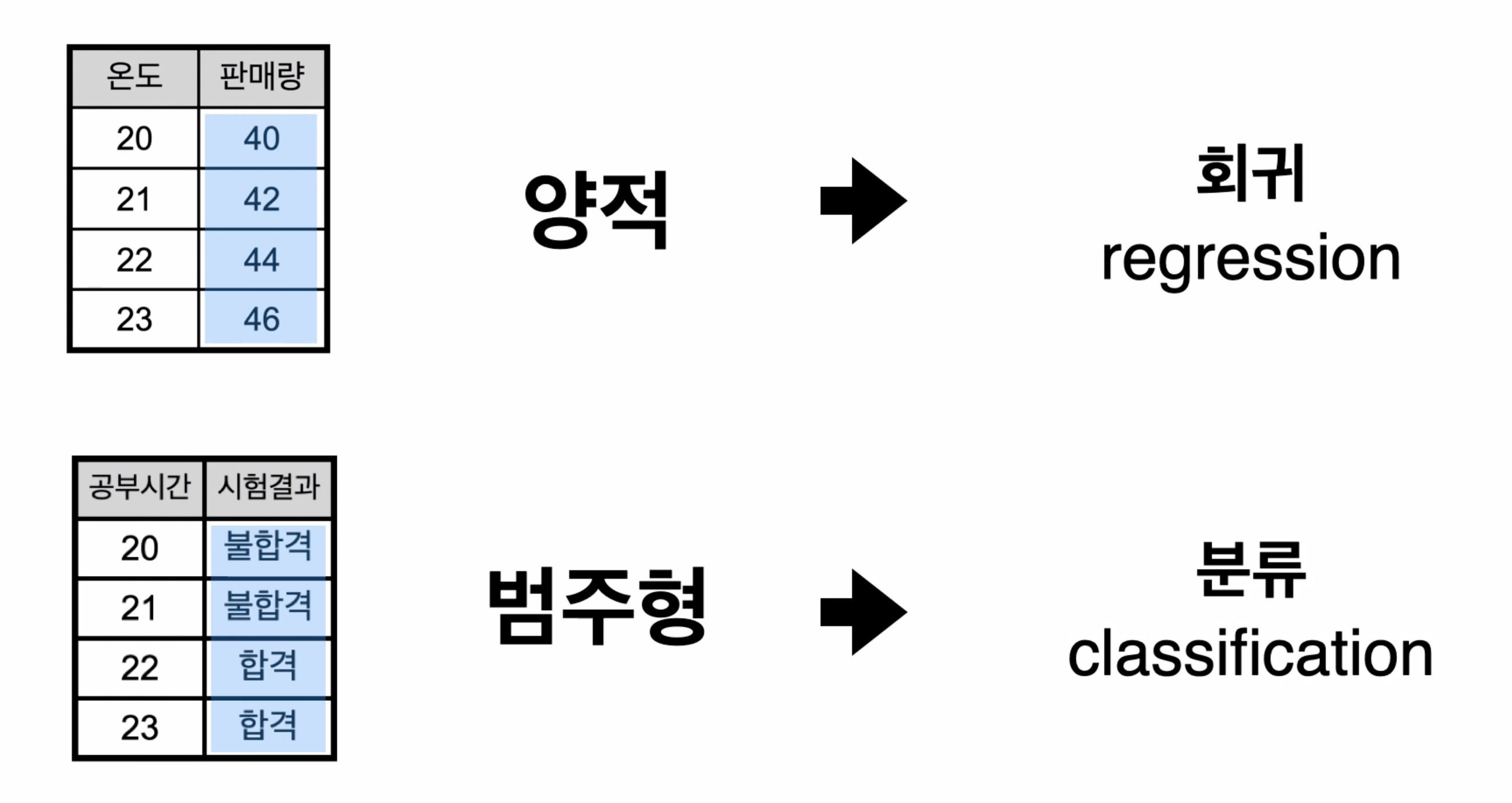
회귀와 분류를 간단하게 설명을 하자면,
회귀( regression )는 종속변수가 숫자인 경우를 뜻하고, 분류( classification )는 종속변수가 숫자가 아닌 경우를 뜻한다.
보스턴 집값 예측과 레모네이드 값 예측은 종속변수가 숫자라서 회귀 알고리즘을 사용하였고,
아이리스 품종 예측은 종속변수가 글자라서 분류 알고리즘을 사용할 예정이다.
자 그럼 과거의 데이터를 먼저 가져와서 간단하게 정리를 해보자.
데이터의 경로는 아래에 참조하겠다.
https://raw.githubusercontent.com/HyunjunKim1/Opentutorial_Deeplearning/main/iris.csv
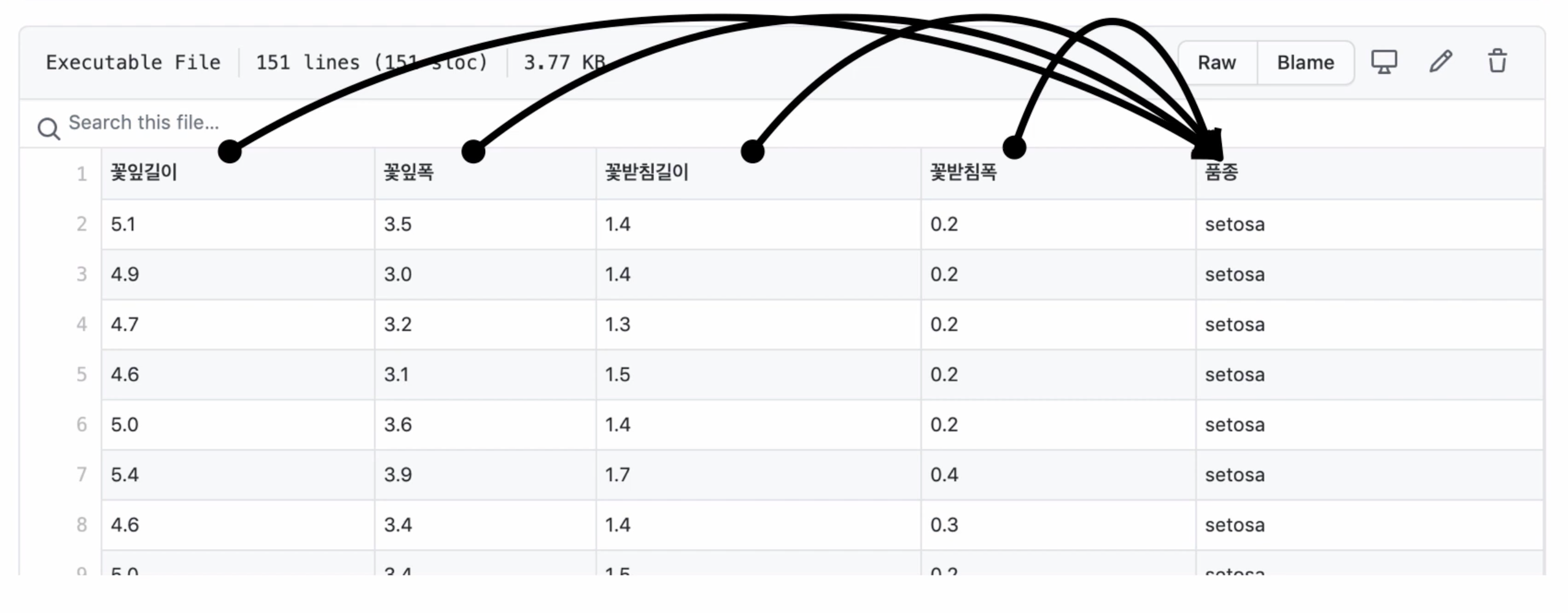
꽃잎의 길이, 꽃잎 폭, 꽃받침 길이, 꽃받침 폭이 품종을 결정한다.
여기서 품종은 숫자가 아니기 때문에 기존과 같은 공식을 사용할 수가 없다.
아래를 참조해보자. 아래는 아이리스 품종분류를 하기위해 간단하게 만들어진 코드이다.

여기서 전의 회귀 알고리즘의 코드와 다른점이 몇개 보인다.
pandas의 get_dummies와 activation=softmax, 그리고 loss='categorical_crossentropy' 이다.
우선 get_dummies는 원핫인코딩이라고 한다.
y = w1x1 ... wnxn + b 와 같은 수식에 범주형 데이터를 사용하는건 이치에 맞지 않는다.
하지만 범주형 데이터를 원핫인코딩을 해주면 된다.
품종이 'setosa', 'virginica', 'versicolor' 3가지가 있다.
그럴경우 원핫인코딩을 해주면 아래와 같이 바뀐다.
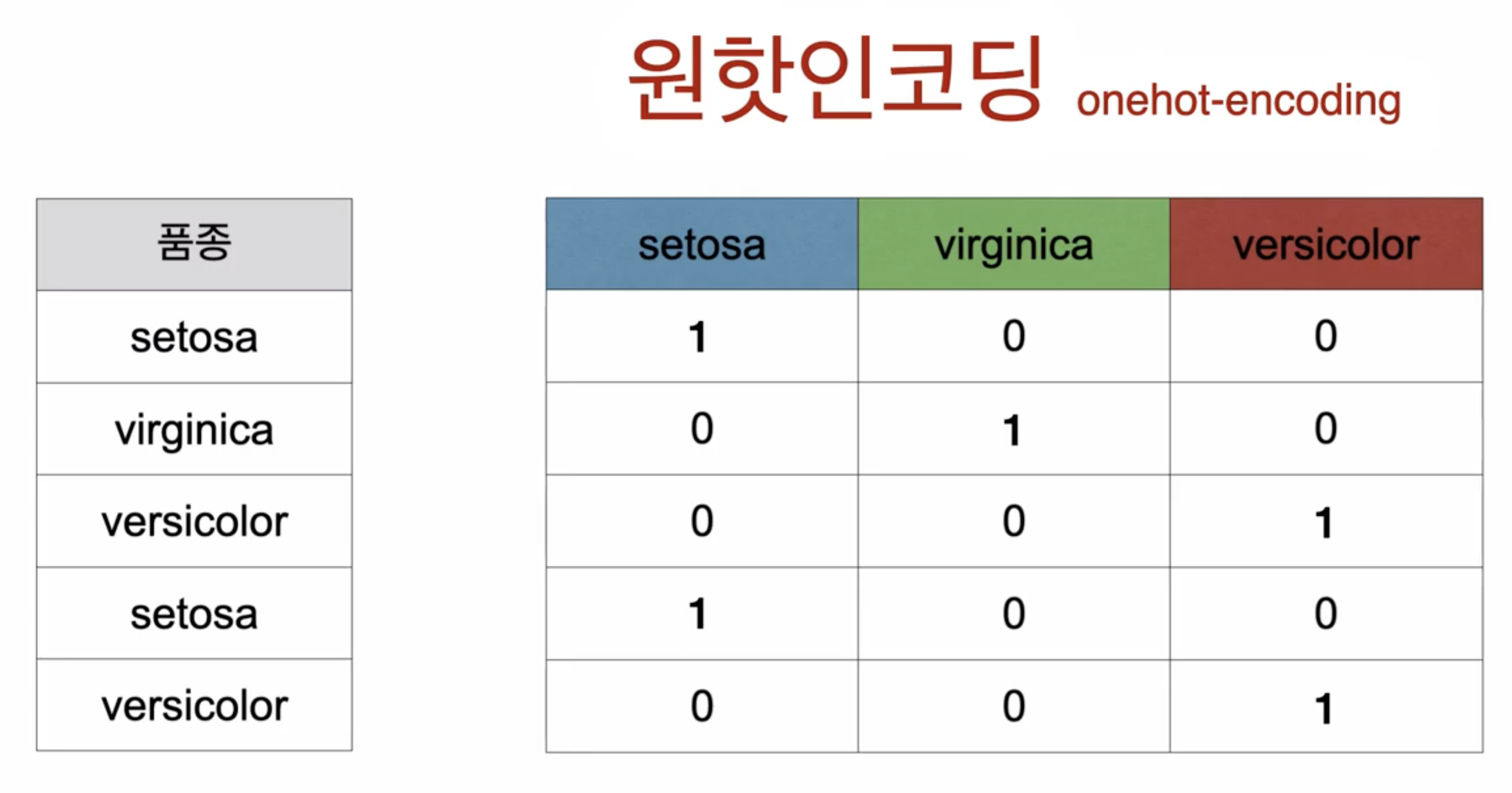
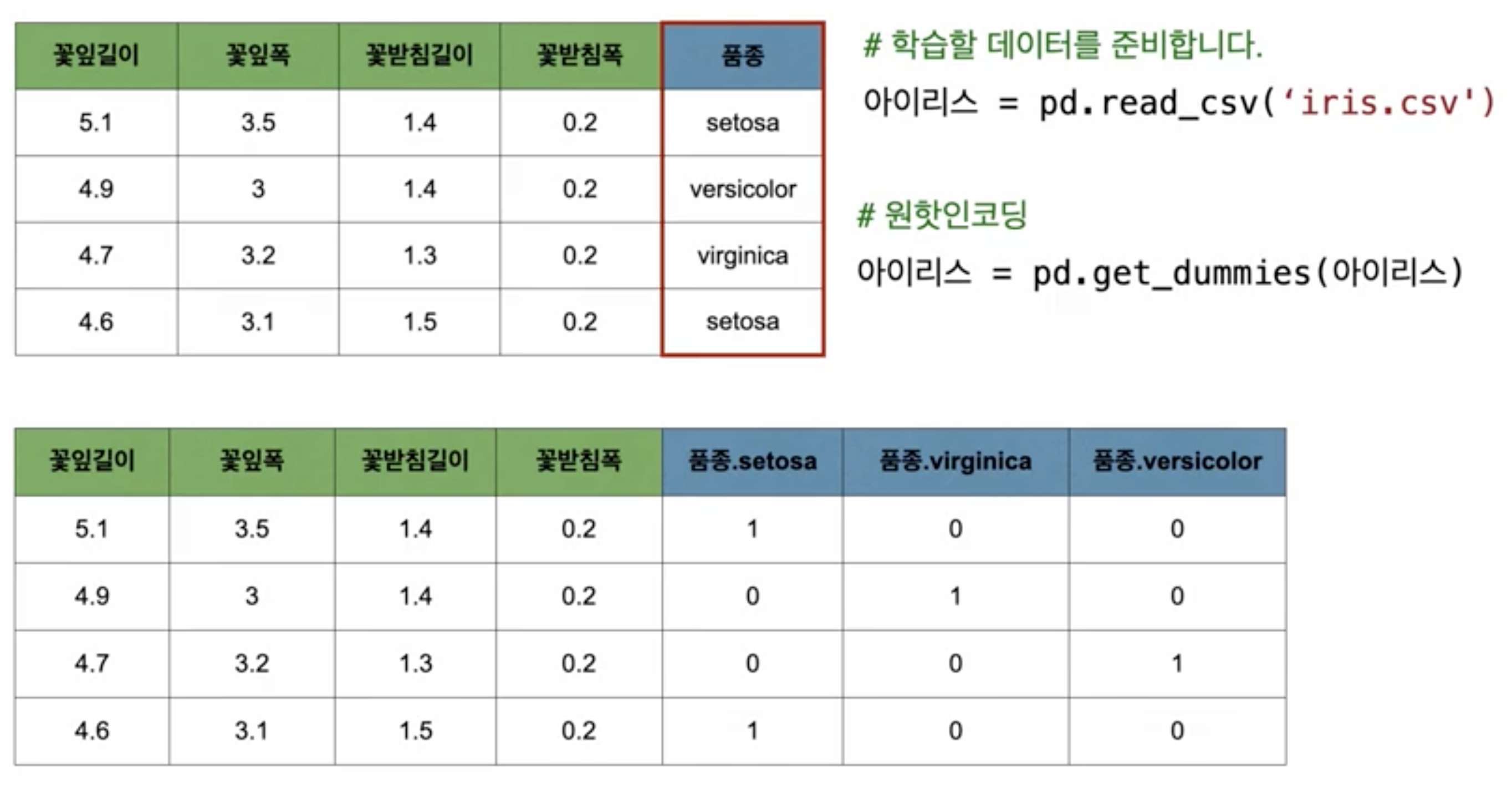
이렇게 원핫인코딩을 해주면 범주형 데이터에서 숫자로 컨버팅이 되고, 수식이 사용이 가능하다.
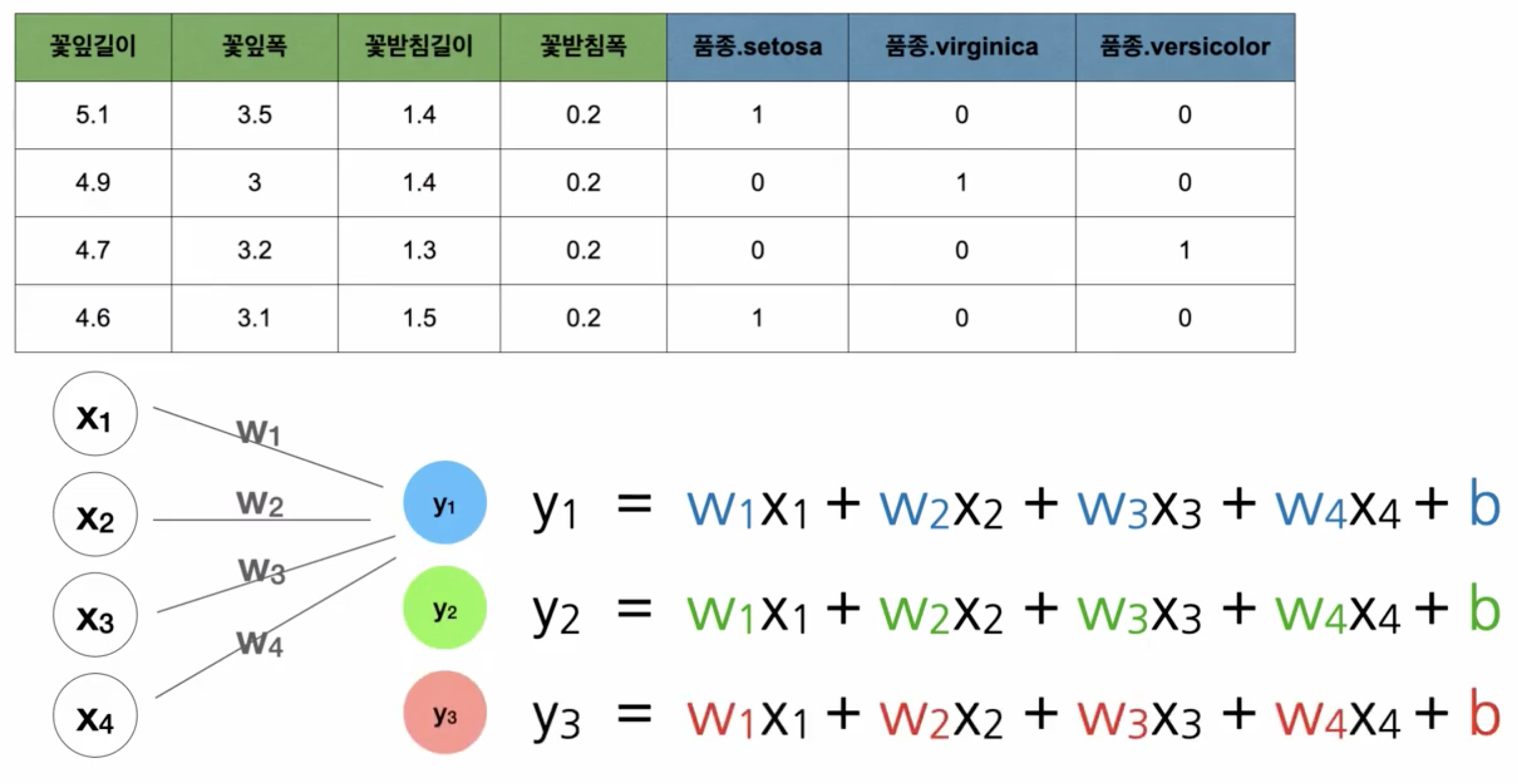
get_dummies를 사용하게 되면, 해당 칼럼에서 모든 범주형 데이터를 숫자로 인코딩 해주게된다.
그럼 컴퓨터는 3가지 종속변수에 대한 가중치를 찾아야하는데 인코딩을 해주기때문에 가능해진다. 아래 이미지를 확인해보자.
그리고 softmax와 crossentropy에 관해서는 아래 포스팅을 참고하자.
https://hyun-jun5.tistory.com/81
[Machine learning] One-hot encoding와 Softmax Regression, Cross-entropy란?
Softmax Regrssion (소프트맥스 회귀) 란? 소프트맥스 회귀는 다중 분류에 대한 회귀이다. 사실상 일반적으로 회귀는 bool문과 같이 0 또는 1, true 또는 false 식으로 상반되는 값을 분류하는데 사용된다.
hyun-jun5.tistory.com
그럼 실제로 예제를 한번 풀어보도록 하자.
위에서의 파일 경로를 가져와 csv 파일을 읽어온다.
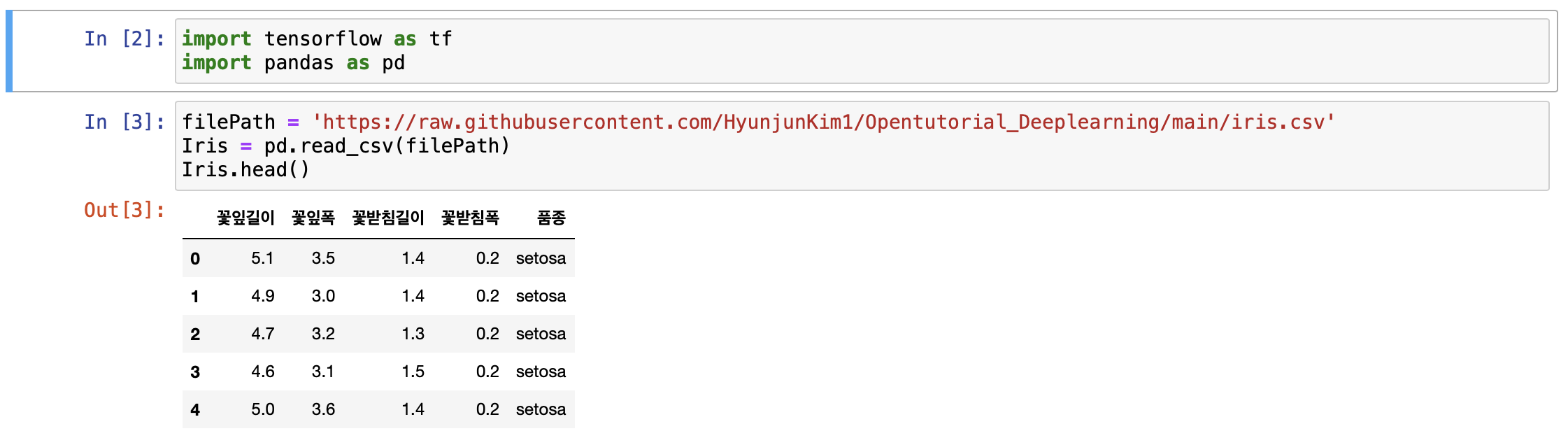
이후 위에서 말했듯, 품종에 있는 범주형 데이터들을 원핫 인코딩을 해주어야한다.
그리고 인코딩 되어있는 독립변수와 종속변수들을 확인해보자.
아래를 참조하자.

독립변수가 총 4개이기에 shape 값은 4가 되고,
종속변수가 총 원핫인코딩으로 3개가 되었기에, Dense에 3을 넣어준다.
또한 이는 분류 알고리즘이기 때문에, Dense에 회귀 방식을 softmax로 사용해야한다.

그리고 loss를 categorical_crossentropy로 바꿔주어야 한다.
그리고 우리가 보기좋게, 사람이 보기좋은 지표로 보기 위해 metrics = 'accuracy'를 추가해준다.
첫 10번 반복을 통해 모델에 학습시켜보자.
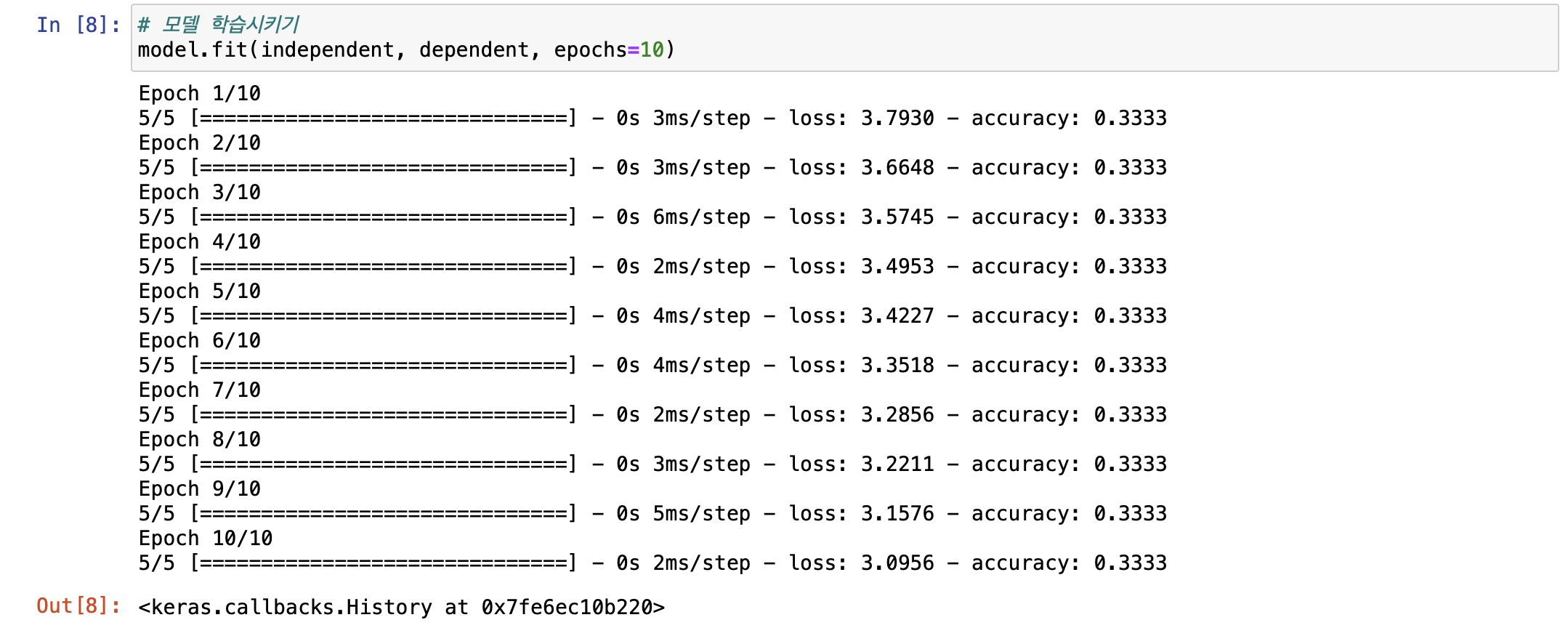
loss가 꾸준히 줄어드는걸로 미루어 보아 더 학습시켜도 무난하게 학습이 될것 같다.
또한 accuracy 값이 33%밖에 안되 많이 낮아서 더 학습을 시켜보자.
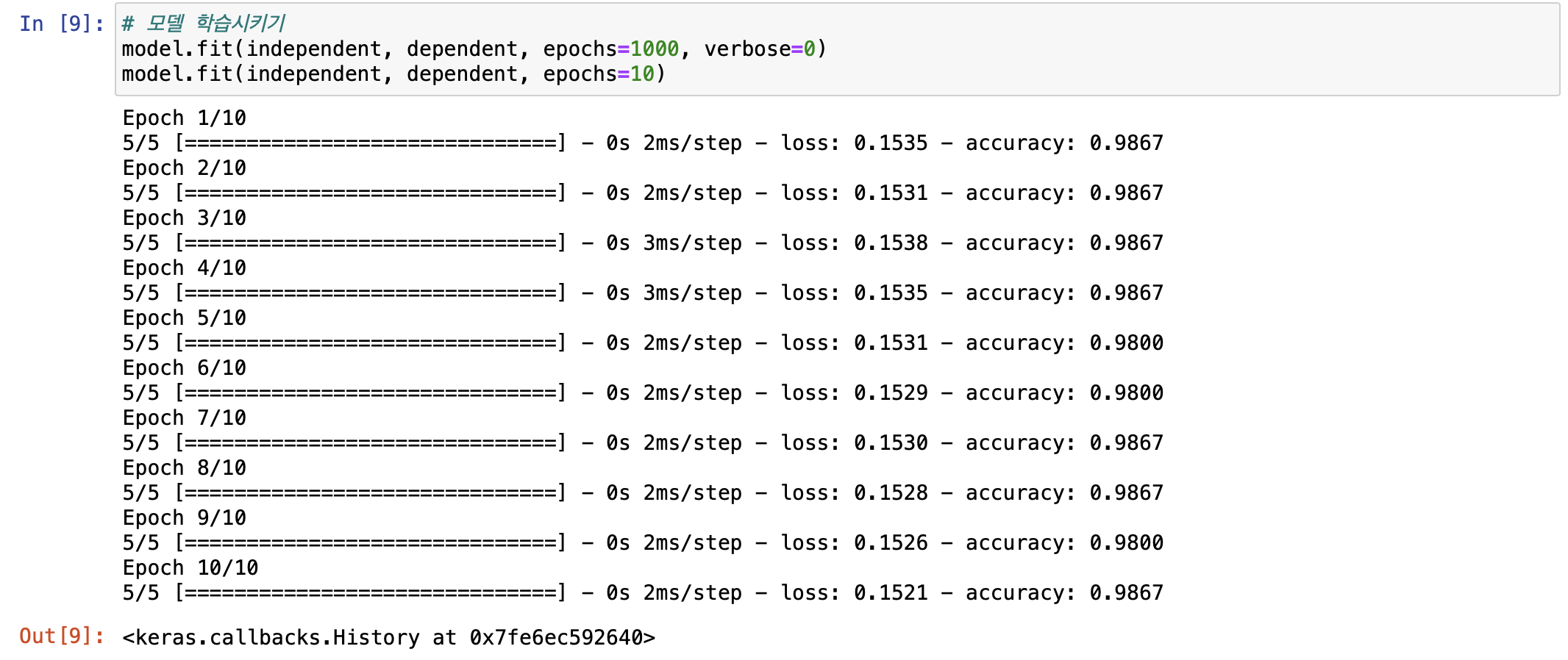
1000번 정도 더 학습을 시켜주었더니, 정확도 98%에 loss도 많이 떨어진 것을 확인하였다.
자 그럼 모든 데이터를 하나씩 확인해보기가 힘드니, 처음 5개의 데이터와 끝 5개의 데이터를 확인해보자.
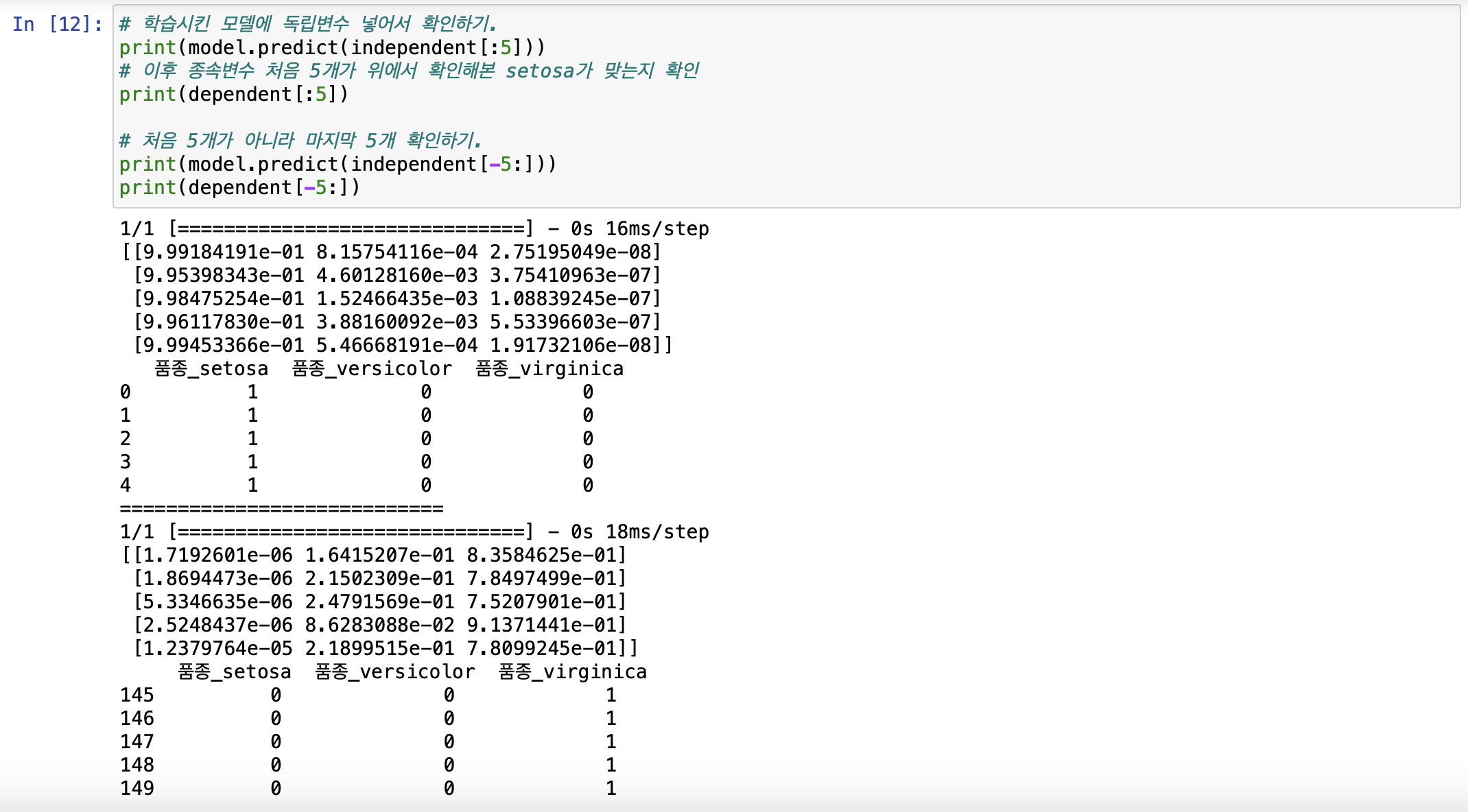
확인을 해 보았더니, 처음 5개의 품종은 setosa일 확률이 0.x 확률로 맞다고 나온다.
물론 끝 5개의 품종은 virginica일 확률 역시도 0.x 확률로 맞다고 나온다.
아주 높은확률로 데이터가 모델에 학습이 잘 된것을 확인할 수 있다.
아래 전체코드를 첨부할테니 참조하자.
Code ( Python )
import tensorflow as tf
import pandas as pd
filePath = 'https://raw.githubusercontent.com/HyunjunKim1/Opentutorial_Deeplearning/main/iris.csv'
Iris = pd.read_csv(filePath)
Iris.head()
# 원핫 인코딩
Iris = pd.get_dummies(Iris)
# 독립변수와 종속변수
independent = Iris[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
dependent = Iris[['품종_setosa', '품종_versicolor', '품종_virginica']]
print(independent.shape, dependent.shape)
# 모델 구조 만들기
X = tf.keras.layers.Input(shape=[4])
Y = tf.keras.layers.Dense(3, activation='softmax')(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')
# 모델 학습시키기
model.fit(independent, dependent, epochs=1000, verbose=0)
model.fit(independent, dependent, epochs=10)
# 학습시킨 모델에 독립변수 넣어서 확인하기.
print(model.predict(independent[:5]))
# 이후 종속변수 처음 5개가 위에서 확인해본 setosa가 맞는지 확인
print(dependent[:5])
# 처음 5개가 아니라 마지막 5개 확인하기.
print(model.predict(independent[-5:]))
print(dependent[-5:])
# 가중치 출력해서 확인해보기!
print(model.get_weights())참조
https://www.youtube.com/watch?time_continue=376&v=bu8g-Bs4Oyk&feature=emb_title
'🔥 Programming > ML & DL' 카테고리의 다른 글
| [Tensorflow / Deep learning] 은닉층 (Hidden Layers) (0) | 2022.12.03 |
|---|---|
| [Machine learning] One-hot encoding와 Softmax Regression, Cross-entropy란? (0) | 2022.11.30 |
| [Tensorflow / Deep learning] 보스턴 집값 예측 (1) | 2022.11.29 |
| [Tensorflow / Deep learning] 레모네이드 판매 예측 (0) | 2022.11.28 |